
The Illustrated Sparse Attention
A visual guide to understanding how modern transformers handle long sequences efficiently

The Problem: When Attention Becomes Too Expensive
Imagine you’re at a party with 100 people. In a traditional transformer (with dense attention), every person needs to have a conversation with every other person. That’s 100 × 100 = 10,000 conversations!
Now imagine a party with 10,000 people. That becomes 100 million conversations. This is the quadratic scaling problem of attention mechanisms.
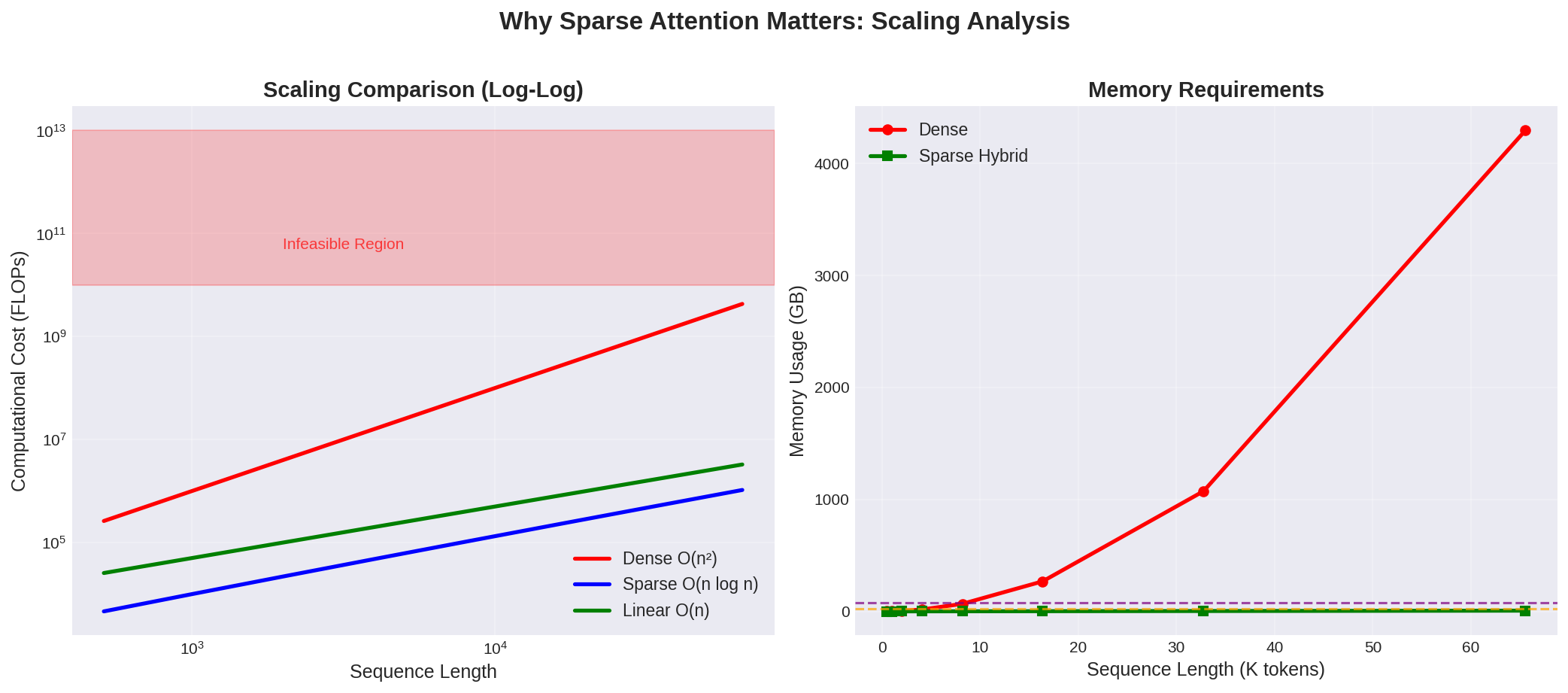
Dense Attention Cost: O(n²)
- 100 tokens → 10,000 computations
- 1,000 tokens → 1,000,000 computations
- 10,000 tokens → 100,000,000 computations 💀
Real-World Impact
This quadratic cost means:
Long documents become impossible to process
GPU memory runs out quickly
Inference speed drops dramatically
Energy consumption skyrockets
For example, processing a single book chapter (8,000 tokens) with dense attention would require 64 million attention computations. That’s why GPT-3 was originally limited to 2,048 tokens, and why longer context windows were such a breakthrough.
The Solution: Sparse Attention
Sparse attention is based on a simple observation:
Not every word needs to look at every other word to understand the meaning.
Instead of everyone talking to everyone, we strategically choose who talks to whom.
The Core Idea
Dense Attention: Every token ↔ Every token
Sparse Attention: Every token ↔ Selected subset of tokens
Think of it like this:
Dense attention = Broadcasting to the entire stadium
Sparse attention = Strategic conversations with the right people
The Three Types of Sparse Attention
Let’s explore the three fundamental patterns that make sparse attention work.

1. Local Attention
What it is: Each token only attends to its immediate neighbors within a fixed window.
The Intuition: Most linguistic dependencies are local. When you read “The quick brown fox,” the word “brown” mainly needs to understand “quick” and “fox” — not words from three sentences ago.
Sentence: “The cat sat on the mat near the door”
Token “sat” attends to:
[The, cat, sat, on, the] ← window of 5
↑ ↑ ME ↑ ↑
Cost: O(n × window_size)
Real-world analogy: In a classroom, you mainly talk to people sitting near you.
Strengths:
✅ Captures syntax and local coherence
✅ Very efficient (linear in sequence length)
✅ Works great for tasks with local structure
Weaknesses:
❌ Can’t capture long-range dependencies
❌ Information flow is slow across distance
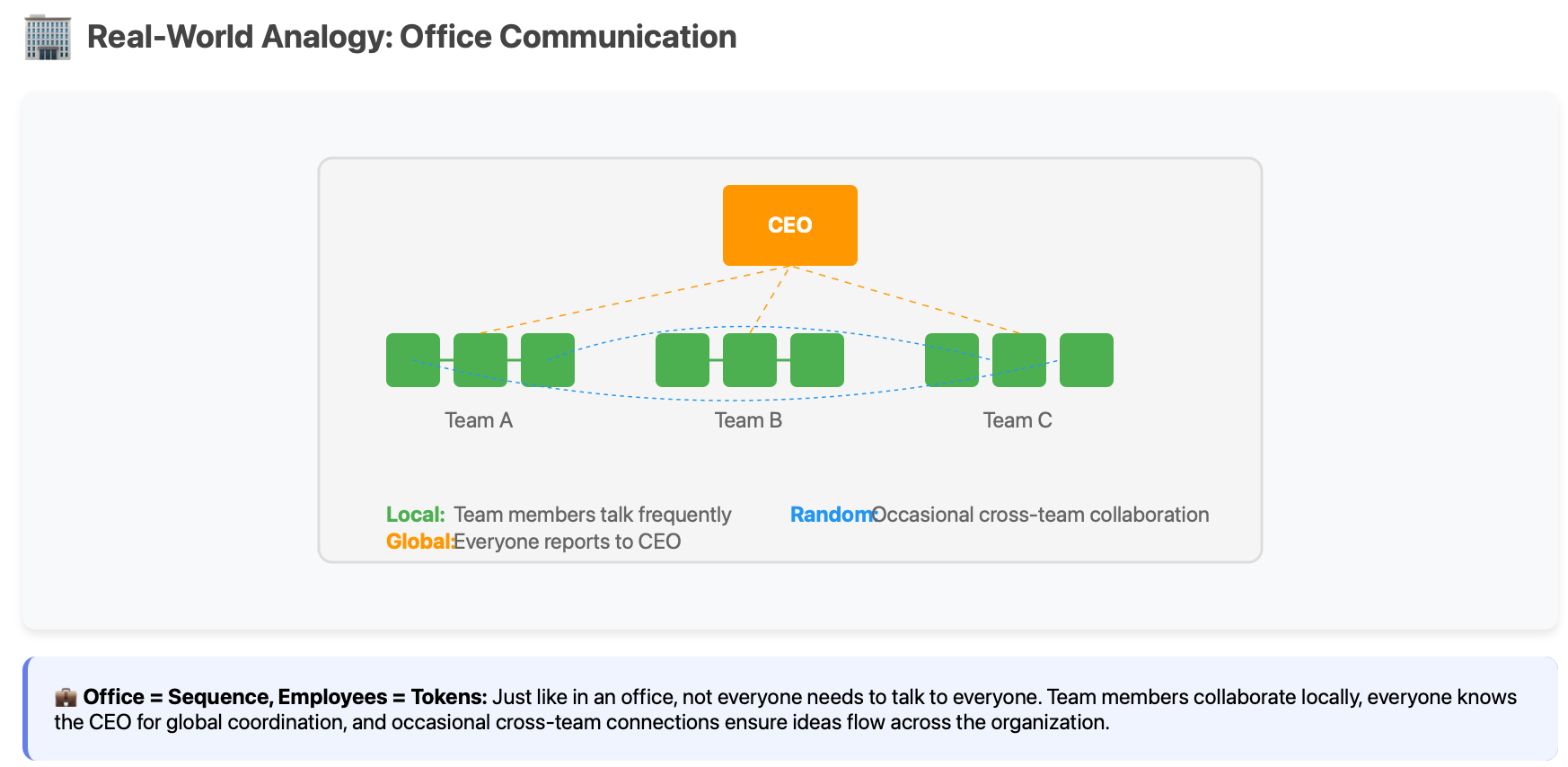
2. Global Attention
What it is: A few special “anchor” tokens that everyone can see and that can see everyone.
The Intuition: Some tokens are more important — like [CLS] tokens, sentence beginnings, or paragraph starts. These act as information hubs.
Regular tokens: Attend locally + to global tokens
Global tokens: Attend to ALL tokens
Example with [CLS] as global:
[CLS] ← sees everything
↕
“The cat sat on the mat”
↑___↑___↑___↑___↑___↑ (all can see [CLS])
Real-world analogy: In a company, everyone knows the CEO, and the CEO knows everyone — but not everyone knows each other.
Strengths:
✅ Maintains document-level coherence
✅ Efficient information routing
✅ Natural for hierarchical structures
Weaknesses:
❌ Global tokens can become bottlenecks
❌ Still misses some medium-range patterns
3. Random/Strided Attention
What it is: Each token randomly connects to a few distant tokens, or connects at regular intervals.
The Intuition: Creates “shortcuts” across the sequence, like a small-world network. Any token can reach any other token in just a few hops.
Strided Pattern (every 3rd token):
Token₁ → Token₄ → Token₇ → Token₁₀
Random Pattern:
Token₅ → {Token₂, Token₉, Token₁₅} (randomly selected)
This creates a “small world” effect!
Real-world analogy: In social networks, you have random long-distance friends who connect you to completely different social circles.
Strengths:
✅ Guarantees connectivity across sequence
✅ Prevents information islands
✅ Theoretically proven to maintain expressiveness
Weaknesses:
❌ Less interpretable
❌ May miss systematic patterns
Hybrid Sparse Attention: The Best of All Worlds
Now here’s where it gets exciting. Hybrid sparse attention combines multiple patterns to overcome each method’s weaknesses.
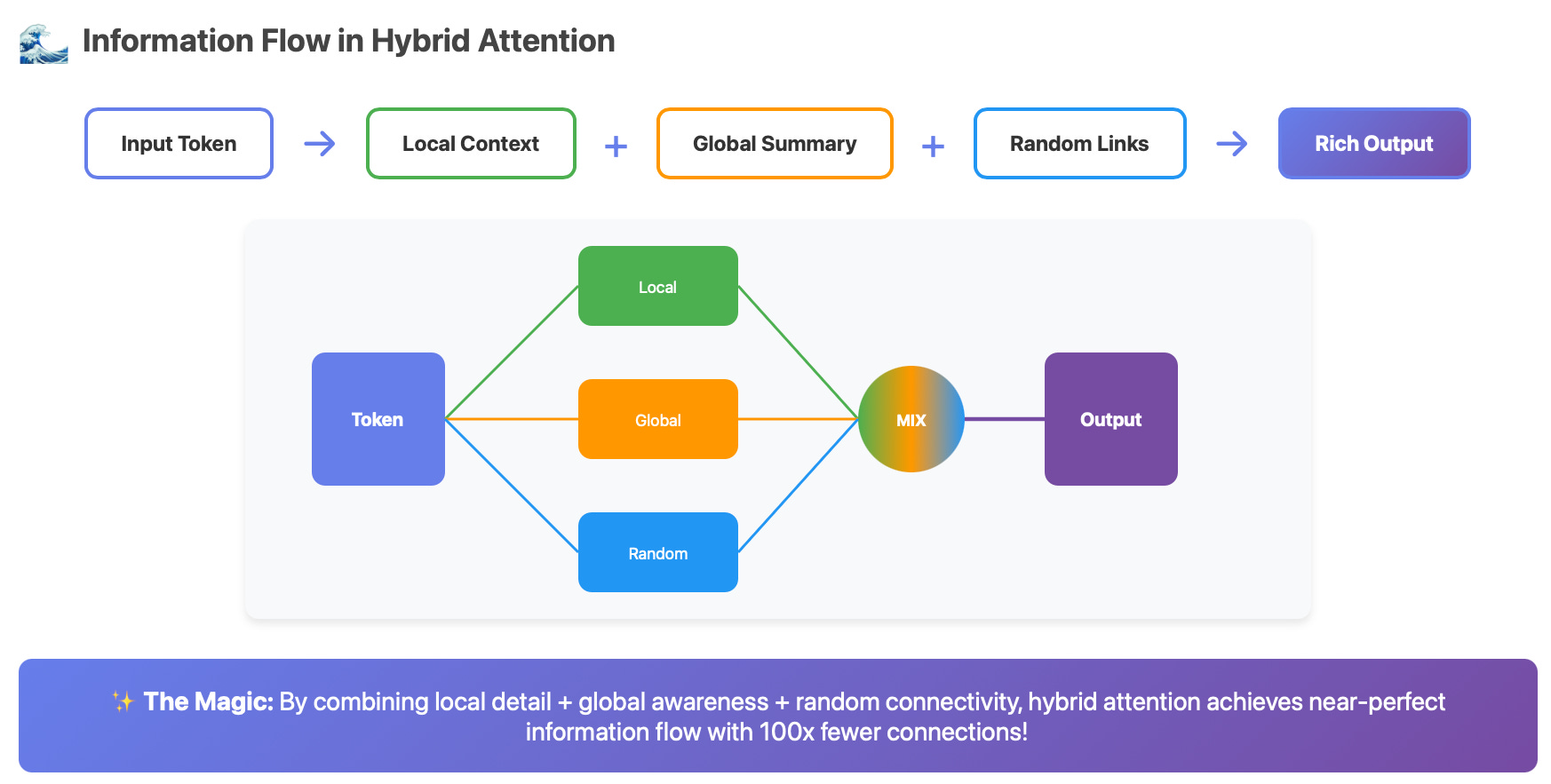
The Formula
Hybrid Attention = Local + Global + Random
Each token’s attention set becomes:
attention_set = (
local_neighbors # Fine-grained local understanding
∪ global_tokens # Document-level coherence
∪ random_connections # Long-range information flow
)
How It Works in Practice
Let’s trace through a 1,000-token document:
Token #500 attends to:
├── Local: Tokens 496-504 (window of 9)
├── Global: Tokens [0, 250, 500, 750] (section anchors)
└── Random: Tokens [127, 891] (random connections)
Total: 15 tokens instead of 1,000!
Speedup: 66x
Visual Representation
Traditional Dense Attention:
[Every token] ←→ [Every token]
Total connections: n²
Hybrid Sparse Attention:
┌─────────────────────────────────┐
│ LOCAL: Token ←→ Nearby tokens │
│ + │
│ GLOBAL: Token ←→ Hub tokens │
│ + │
│ RANDOM: Token ←→ Random tokens │
└─────────────────────────────────┘
Total connections: ~n × (w + g + r)
where w=window, g=globals, r=random samples
Real-World Examples
BigBird (Google Research)
Pattern: Local (sliding window) + Global (CLS/SEP tokens) + Random
Innovation: Theoretically proven to be as powerful as full attention
Use case: Document understanding, long-form QA
Longformer (AllenAI)
Pattern: Local (sliding window) + Global (task-specific)
Innovation: Different window sizes for different layers
Use case: Long document classification, summarization
Sparse Transformer (OpenAI)
Pattern: Strided + Local patterns
Innovation: Factorized attention patterns
Use case: Generating long sequences (images, music)
The Magic: Why Hybrid Works
1. Information Flow Guarantee
With the combination of local + global + random:
Any token can reach any other token in ~2-3 hops
No information islands form
Critical information propagates quickly
2. Complementary Strengths
Pattern What it captures What it misses Local Syntax, phrases Long-range deps Global Document structure Mid-range patterns Random Connectivity Systematic patterns Hybrid All of the above! Very little
3. Adaptive Complexity
The model can learn to:
Use local attention for understanding phrases
Use global attention for document-level reasoning
Use random attention for discovering unexpected connections
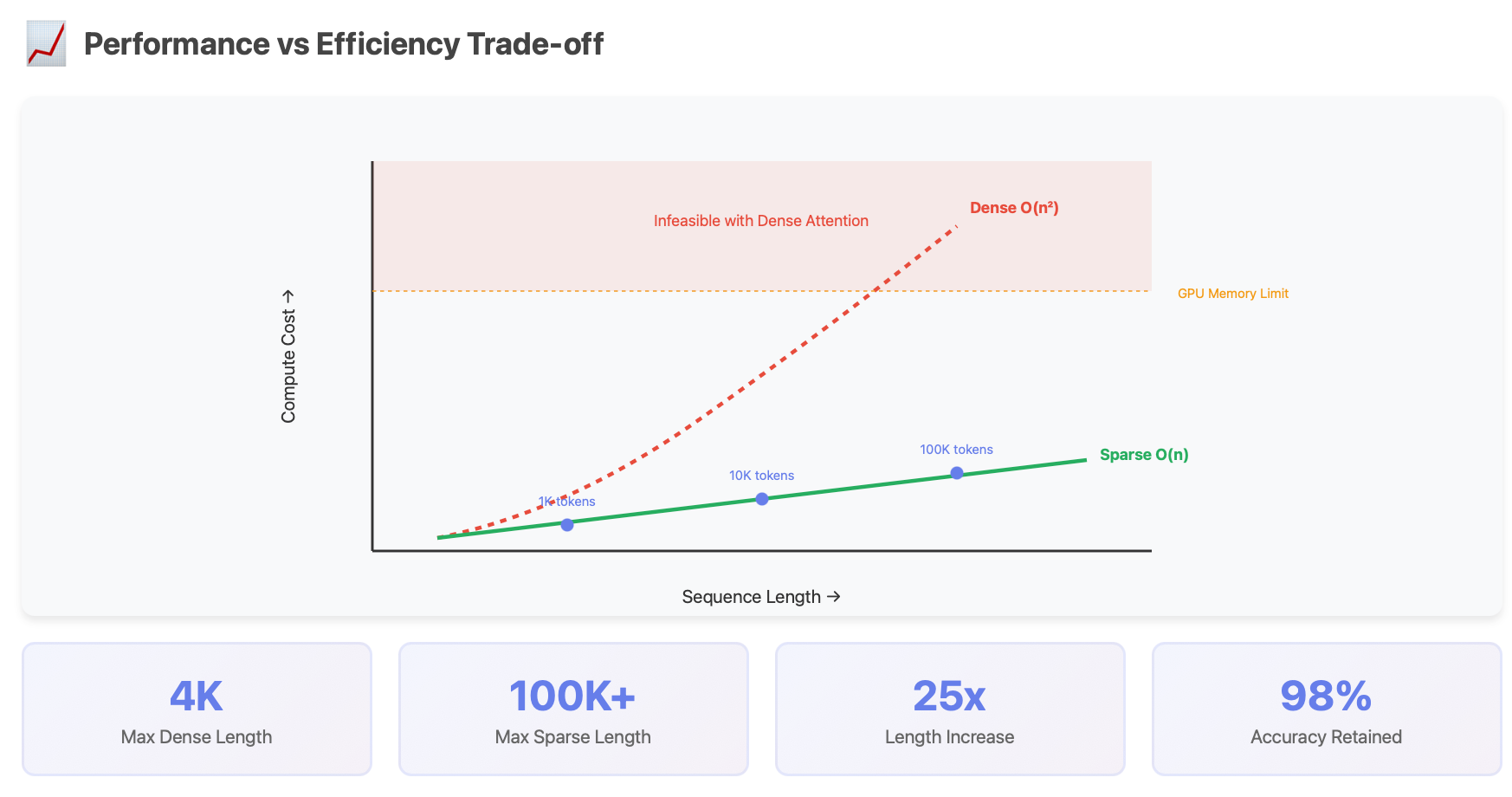
Practical Impact: The Numbers
Here’s what sparse hybrid attention achieves:
Metric Dense Attention Sparse Hybrid Improvement Memory O(n²) O(n) 100-1000x less Speed O(n²) O(n log n) 10-100x faster Max Length ~4K tokens ~100K tokens 25x longer Performance 100% 95-98% Minimal loss
Code Intuition
Here’s simplified pseudocode to build intuition:
def hybrid_sparse_attention(query, key, value, position):
# Define attention targets
local_indices = range(position - 32, position + 32)
global_indices = [0, 500, 1000, 1500] # Document anchors
random_indices = random.sample(range(seq_len), 3)
# Combine all attention targets
attention_indices = set(local_indices + global_indices + random_indices)
# Compute attention only for selected indices
selected_keys = key[attention_indices]
selected_values = value[attention_indices]
attention_scores = query @ selected_keys.T
attention_weights = softmax(attention_scores)
output = attention_weights @ selected_values
return output
# Instead of O(n²), we now have O(n × k) where k << n
The Future: What’s Next?
2025 and Beyond
Recent developments are pushing sparse attention even further:
Learnable Sparsity: Models that learn which connections to keep
Dynamic Patterns: Attention patterns that adapt based on content
Hierarchical Sparsity: Multi-level sparse patterns for even longer sequences
Hardware Optimization: Custom chips designed for sparse operations
Emerging Architectures
Linear Attention + Sparse State: Combining O(n) attention with sparse updates
Content-Based Sparsity: Attention patterns based on semantic similarity
Multi-Resolution Attention: Different sparsity levels at different scales
Key Takeaways
The Problem: Dense attention’s O(n²) cost limits sequence length
The Solution: Sparse attention selectively connects tokens
The Patterns: Local (neighbors) + Global (hubs) + Random (shortcuts)
The Hybrid: Combining patterns overcomes individual weaknesses
The Impact: 10-100x speedup with minimal performance loss
Sparse hybrid attention isn’t just an optimization — it’s what makes modern long-context AI possible. From processing entire books to understanding hour-long conversations, sparse attention is the secret sauce that makes it all work.