

When fine-tuning large language models (LLMs) for tool calling in enterprise environments, the reward model serves as the North Star that guides your model toward reliable, accurate, and production-ready behavior. Unlike general conversational AI, enterprise tool calling demands precision, consistency, and adherence to strict structural requirements. A well-designed reward model can make the difference between a model that occasionally works and one that your business can depend on.
The stakes in enterprise environments are fundamentally different from academic research or consumer applications. Your LLM needs to interact with critical business systems, APIs, and databases where mistakes can have real consequences. The model must not only understand what tools to call but also how to structure those calls correctly, pass the right parameters, and handle complex multi-step workflows. This creates a unique challenge that requires a sophisticated approach to reward design.
Understanding the Enterprise Challenge
Enterprise tool calling presents a complex landscape of requirements that go far beyond simple function calling. Your organization likely has dozens or even hundreds of different tools, each with its own API specifications, parameter requirements, and business logic. The model needs to navigate this complexity while maintaining the reliability and consistency that enterprise operations demand.
The challenge extends beyond technical accuracy to encompass business context and operational requirements. A model that works perfectly in a controlled testing environment may fail catastrophically when deployed in production if it hasn't been trained to handle the nuances of real-world enterprise workflows. This is where thoughtful reward design becomes crucial, as it shapes how the model learns to balance competing objectives and make decisions under uncertainty.
Enterprise requirements that must be addressed through reward design include:
Reliability: Tools must be called correctly 99%+ of the time, as failures can cascade through business processes
Compliance: Outputs must follow exact formatting specifications to integrate with existing enterprise systems
Auditability: Decision-making process must be transparent for regulatory and governance requirements
Scalability: Consistent performance across diverse use cases and user personas
Integration: Seamless interaction with existing enterprise systems and workflows
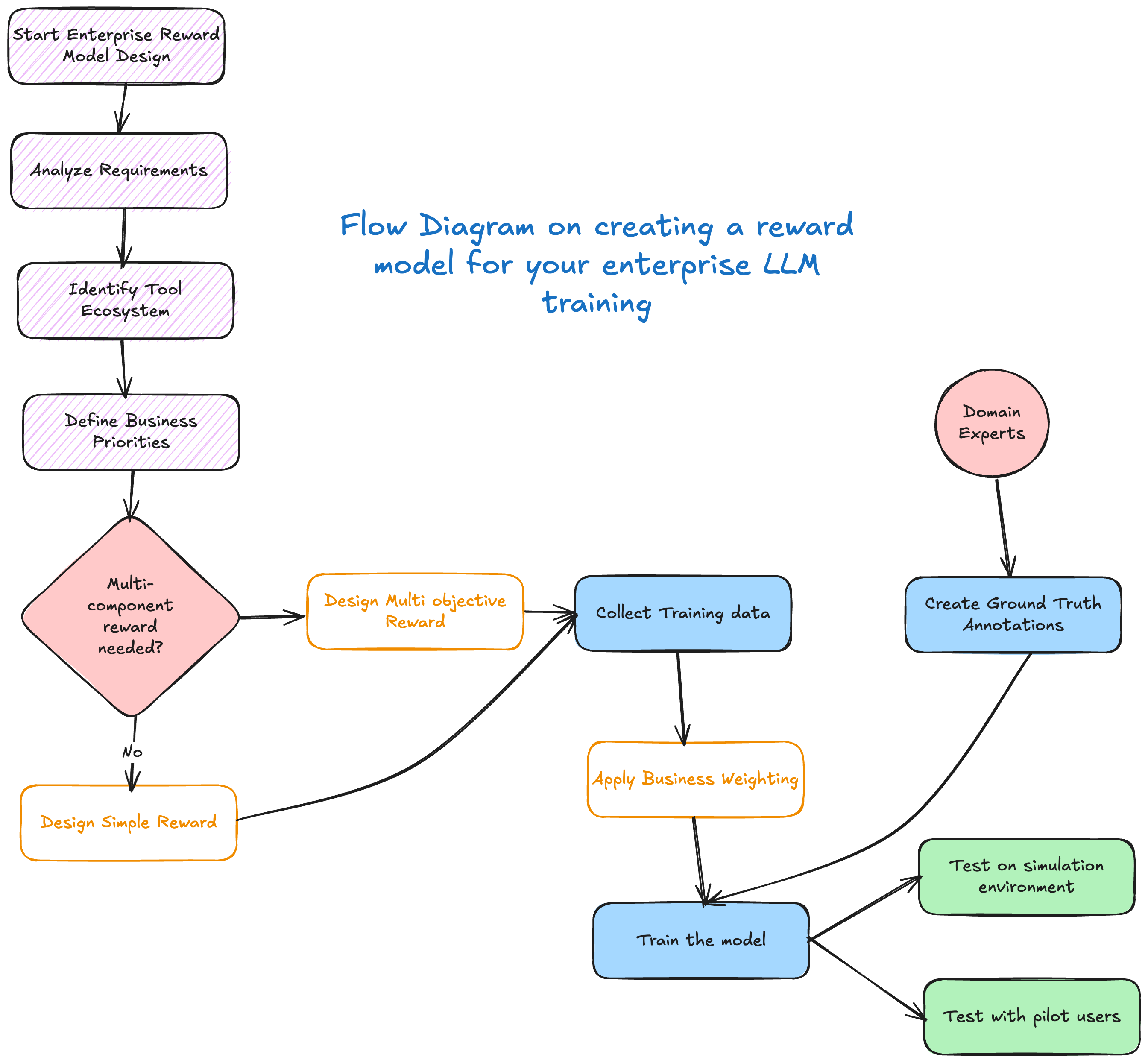
The Dual-Component Reward Architecture
The most effective approach to enterprise tool calling rewards combines two complementary components: format rewards and correctness rewards. This dual architecture ensures your model masters both the structural requirements and the semantic accuracy needed for enterprise deployment. The separation of concerns allows you to tune each component independently while maintaining overall system coherence.
This approach recognizes that enterprise tool calling has two distinct but equally important dimensions of success. A model output might be semantically correct but fail due to formatting issues, or it might be perfectly formatted but contain incorrect tool selections or parameters. By evaluating these dimensions separately, you can provide more nuanced feedback that guides the model toward comprehensive competence.
Format Rewards: Ensuring Structural Compliance
Format rewards evaluate whether your model's output adheres to the expected structure and includes all required components. In enterprise environments, this is non-negotiable—a single missing field or incorrectly formatted response can break entire workflows. The binary nature of format rewards reflects the reality that structural compliance is typically an all-or-nothing proposition in enterprise systems.
The implementation of format rewards requires careful consideration of your specific enterprise requirements. You need to define exactly what constitutes proper formatting in your context, including the presence of required fields, correct ordering of elements, and proper use of special tokens or delimiters. This specification becomes the foundation for your format reward calculation.
The format reward can be implemented as a simple binary function:
Rformat = {
1, if all required fields present and correctly ordered
0, otherwise
}
Key elements that your format reward should validate include the presence of thought processes where the model explains its reasoning, properly formatted tool calls structured as valid JSON, response structures that follow your enterprise schema, and correct placement of special tokens like <think>, <tool_call>, and <response> in their designated positions.
Enterprise considerations for format rewards extend beyond basic structural validation. You need to define strict schemas for each tool in your ecosystem, ensuring that the reward function can validate against the specific requirements of your business systems. Implement validation rules that mirror your production API requirements, as this ensures consistency between training and deployment environments. Consider versioning for schema changes across your tool landscape, as enterprises often have multiple versions of tools running simultaneously. Build in flexibility for optional versus required fields, as this reflects the reality of enterprise API design where some parameters may be conditional or context-dependent.
Correctness Rewards: Evaluating Semantic Accuracy
While format rewards ensure structural compliance, correctness rewards evaluate whether the model is making the right decisions about tool usage. This component typically uses a more nuanced scoring system that can capture partial correctness, recognizing that semantic accuracy often exists on a spectrum rather than as a binary outcome.
The correctness reward system acknowledges that enterprise tool calling involves complex decision-making processes where partial credit may be appropriate. A model might select the correct tool but use suboptimal parameters, or it might choose a reasonable alternative approach that wasn't anticipated in the ground truth. A sophisticated correctness reward system can capture these nuances and provide appropriate feedback.
The correctness reward evaluation follows a three-tier framework that breaks down the complexity of tool calling into manageable components. Each tier addresses a different aspect of tool calling accuracy, allowing you to identify specific areas where the model excels or needs improvement.
Tool Name Matching represents the foundation of correct tool usage. This component measures how well the model selects appropriate tools from your enterprise toolkit using the formula
rname = |NG ∩ NP| / |NG ∪ NP|.
Consider weighting this component heavily, as selecting the wrong tool can have cascading effects in business workflows. The intersection over union approach provides a balanced measure that accounts for both precision and recall in tool selection.
Parameter Name Matching evaluates whether the model identifies the correct parameters for each tool call through
rparam = Σ |keys(PG) ∩ keys(PP)| / |keys(PG) ∪ keys(PP)|.
In enterprise settings, parameter schemas can be complex, with required fields, optional fields, and conditional requirements. This component ensures that the model understands the interface requirements of each tool and can navigate the complexity of enterprise API specifications.
Parameter Value Matching assesses whether the model provides accurate values for each parameter using rvalue = Σ Σ 1[PG[k] = PP[k]]. This is often the most challenging component, as it requires understanding context, data types, and business logic. The model must not only know what parameters to use but also how to extract or derive the appropriate values from the conversation context.
Enterprise-Specific Reward Considerations
Business Context Weighting
Different tools in your enterprise ecosystem likely have varying criticality levels, and your reward model should reflect these differences. A mistake in a financial transaction tool has far different consequences than an error in a content management system. By implementing weighted rewards based on business impact, you can guide your model to be more careful with high-stakes operations while maintaining efficiency for routine tasks.
The weighting strategy should consider multiple factors that reflect your business priorities. Business impact weighting assigns higher reward magnitudes to critical financial or compliance tools, ensuring that the model learns to prioritize accuracy in these areas. Usage frequency weighting gives more attention to commonly used tools during training, improving overall user experience by optimizing the most frequent interactions. Error cost weighting applies penalty multipliers to tools where mistakes are expensive, creating stronger incentives for accuracy in high-risk scenarios.
Multi-Step Workflow Rewards
Enterprise workflows often involve chains of tool calls where the output of one tool becomes the input for another. Traditional reward models that evaluate individual tool calls in isolation may miss the broader context of workflow coherence. Your reward design should account for these dependencies and encourage the model to think about tool calling as part of larger business processes.
Multi-step workflow rewards should evaluate several aspects of sequence coherence. Workflow coherence assessment determines whether tools are called in logical sequence, considering the dependencies between different business operations. Dependency handling evaluation checks whether the model properly uses outputs from previous steps, ensuring that information flows correctly through complex workflows. Efficiency rewards prefer shorter, more direct paths to solutions, encouraging the model to find optimal approaches rather than unnecessarily complex sequences.
Error Recovery and Graceful Degradation
Enterprise systems need to handle failures gracefully, and your reward model should encourage this behavior. Rather than simply penalizing errors, consider designing rewards that incentivize the model to detect problems early, communicate issues clearly, and attempt recovery strategies when possible. This approach builds resilience into your tool calling system.
Error recovery rewards should encourage several types of beneficial behavior. Error checking rewards incentivize models that validate tool responses before proceeding, catching problems early in the workflow. Fallback strategy rewards promote alternative approaches when primary tools fail, ensuring that business processes can continue even when preferred methods are unavailable. User communication rewards value clear error messages and status updates, keeping human users informed about system state and potential issues.
Implementation Best Practices
Data Collection and Annotation
The quality of your reward model depends heavily on the quality of your training data and ground truth annotations. In enterprise contexts, this means working closely with domain experts who understand not just the technical aspects of tool calling but also the business context and user expectations. The annotation process should capture not just what the model should do, but why those choices are optimal in your enterprise environment.
Ground truth generation requires collaboration with domain experts to create high-quality training examples that reflect real enterprise scenarios. Using actual enterprise scenarios rather than synthetic data ensures that your model learns from realistic examples that it will encounter in production. Implementing inter-annotator agreement protocols maintains consistency across different experts and annotation sessions. Creating diverse examples that cover edge cases and error conditions prepares your model for the full range of situations it might encounter.
Annotation guidelines should establish clear criteria for "correct" tool usage in your specific context, as what constitutes correctness may vary between organizations and use cases. Define handling procedures for ambiguous scenarios where multiple approaches might be valid. Create rubrics for partial credit assignment that reflect the relative importance of different aspects of tool calling accuracy. Document decision-making processes for future reference, ensuring that your annotation standards remain consistent over time.
Reward Signal Quality
Maintaining high-quality reward signals requires ongoing attention to potential issues that can emerge during training. Reward hacking, where models learn to exploit specific aspects of the reward function rather than learning the intended behavior, is a particular concern in complex enterprise environments. Regular monitoring and adjustment of reward signals helps ensure that your model continues to learn meaningful behaviors.
Avoiding reward hacking requires several proactive measures. Regularly audit model outputs for unexpected behaviors that might indicate the model is exploiting unintended reward pathways. Implement diverse evaluation scenarios during training to ensure that the model generalizes well across different contexts. Use held-out test sets that reflect real enterprise complexity, providing an unbiased assessment of model performance. Monitor for overfitting to specific reward components, ensuring that the model learns robust behaviors rather than narrow optimization strategies.
Continuous improvement of reward signals should incorporate feedback from actual enterprise users, as their real-world experience provides valuable insights into model performance. Analyze failure modes in production environments to identify areas where reward design might be improved. Iterate on reward design based on real-world performance metrics, adjusting the balance between different components as you learn more about your specific use case. A/B test different reward formulations to validate improvements before deploying them broadly.
Integration with Enterprise Infrastructure
Your reward model needs to integrate seamlessly with your existing enterprise infrastructure, including MLOps pipelines, monitoring systems, and deployment processes. This integration ensures that reward-based training can be conducted efficiently and that the resulting models can be deployed reliably in your production environment.
Evaluation pipelines should automate reward computation in your MLOps pipeline, reducing manual effort and ensuring consistency across training runs. Integration with existing monitoring and alerting systems allows you to track reward signal quality and model performance over time. Creating dashboards for reward signal analysis provides visibility into training progress and helps identify potential issues. Implementing real-time feedback loops from production usage enables continuous improvement of reward signals based on actual system performance.
Deployment considerations require careful planning to ensure smooth transitions from training to production. Start with conservative reward thresholds to minimize the risk of unexpected behavior in production environments. Implement gradual rollout with canary deployments, allowing you to validate performance on a subset of users before full deployment. Monitor business metrics alongside model performance to ensure that improved reward signals translate into better business outcomes. Maintain rollback capabilities for quick recovery in case issues arise during deployment.
Measuring Success in Enterprise Contexts
Traditional academic metrics may not capture enterprise success, as they often focus on isolated technical performance rather than business impact. Your success metrics should reflect the full scope of what matters in your enterprise environment, including user satisfaction, operational efficiency, and business outcomes.
Business metrics provide the most direct measure of enterprise success. Task completion rates in real workflows indicate whether your tool calling system is actually helping users accomplish their goals. User satisfaction with tool call accuracy reflects the quality of the user experience and the practical utility of your system. Reduction in manual intervention requirements demonstrates the efficiency gains from automated tool usage. Time saved through automated tool usage provides a quantifiable measure of business value.
Technical metrics complement business metrics by providing insight into the underlying system performance. Format compliance rates across different tool categories help identify areas where structural improvements might be needed. Parameter accuracy for high-stakes operations ensures that critical business functions are handled correctly. Latency impacts from reward-driven decision making help balance accuracy with performance requirements. Error recovery success rates indicate how well your system handles unexpected situations.
Operational metrics capture the longer-term sustainability and maintainability of your tool calling system. Model drift over time with changing enterprise tools helps identify when retraining might be necessary. Consistency across different user personas ensures that your system works well for all stakeholders. Scalability to new tools and workflows indicates how well your reward design generalizes to new use cases. Maintenance overhead for reward model updates helps optimize the cost-effectiveness of your approach.
Common Pitfalls and Solutions
Over-Engineering Complexity
One of the most common mistakes in reward model design is creating overly complex reward functions that are difficult to interpret and maintain. While it's tempting to capture every nuance of enterprise tool calling in your reward function, excessive complexity can make the system brittle and hard to debug. The solution is to start with simple, interpretable rewards and add complexity only when justified by clear business needs.
Complex reward functions may seem more sophisticated, but they often create more problems than they solve. They can be difficult for domain experts to understand and validate, making it harder to get buy-in from stakeholders. They may also be more prone to unexpected interactions between different components, leading to unpredictable model behavior. Instead, focus on capturing the most important aspects of tool calling performance in a clear, understandable way.
Ignoring Domain Expertise
Another common pitfall is designing rewards without sufficient input from enterprise users and domain experts. Technical teams may focus on metrics that seem important from a machine learning perspective but miss crucial aspects of what makes tool calling successful in the business context. The solution is to establish regular feedback loops with stakeholders and incorporate their insights into reward design.
Domain experts bring essential knowledge about business processes, user expectations, and the relative importance of different types of errors. They can help identify edge cases that might not be apparent to technical teams and provide guidance on how to handle ambiguous situations. By involving them in the reward design process, you ensure that your model learns to optimize for outcomes that actually matter to your business.
Static Reward Models
Using fixed reward functions that don't adapt to changing enterprise requirements is another common mistake. Enterprise environments are dynamic, with new tools being added, existing tools being modified, and business processes evolving over time. Static reward models can become outdated quickly, leading to degraded performance and user frustration. The solution is to implement versioned reward models with clear upgrade paths and backward compatibility.
Versioned reward models allow you to evolve your reward design over time while maintaining the ability to reproduce previous results. This approach provides flexibility to respond to changing business needs while maintaining the stability that enterprise environments require. Clear upgrade paths ensure that transitions between reward model versions are smooth and predictable.
Future Considerations
As your enterprise tool calling capabilities mature, your reward model should evolve to address increasingly sophisticated scenarios and requirements. The field of enterprise AI is rapidly evolving, and your reward design should be prepared to adapt to new challenges and opportunities.
Advanced scenarios that may require reward model evolution include multi-modal tool interactions that combine text, images, and structured data in complex workflows. Real-time tool call optimization based on system load and resource availability will become increasingly important as enterprise systems scale. Personalized tool selection based on user preferences and historical patterns can improve user experience and efficiency. Integration with emerging enterprise AI governance frameworks will require new approaches to ensuring compliance and accountability.
Emerging challenges in enterprise tool calling include handling tool deprecation and API changes gracefully, as enterprise systems constantly evolve. Managing reward consistency across distributed teams ensures that different parts of your organization can work together effectively. Incorporating privacy and security constraints into reward design becomes increasingly important as regulatory requirements evolve. Balancing automation with human oversight requirements ensures that your system remains trustworthy and controllable.
Conclusion
Designing effective reward models for enterprise LLM tool calling requires balancing multiple competing objectives: structural compliance, semantic accuracy, business value, and operational feasibility. By adopting a dual-component architecture that separately evaluates format and correctness, you can create robust training signals that guide your models toward enterprise-ready performance.
The journey toward effective enterprise tool calling is inherently iterative. You'll need to start with clear, interpretable rewards based on your immediate business needs, then refine and expand as you gain experience and collect real-world feedback. The investment in thoughtful reward design pays dividends in model reliability, user satisfaction, and successful enterprise AI deployment.
Remember that success in enterprise tool calling isn't just about achieving high accuracy scores—it's about building systems that your business stakeholders trust, that integrate seamlessly with existing workflows, and that continue to perform reliably as your enterprise evolves. A well-designed reward model serves as the foundation for achieving these goals, providing the guidance your model needs to navigate the complex landscape of enterprise tool calling successfully.